Search Console Warnings Guide: What Each Alert Means
Written by 

Google's Search Console is one of the most important resources a website owner has at their disposal. It gives you a ton of information about your website, from how it appears in searches to whether or not individual pages are indexed to if Google detects errors in your site code or formatting that can hinder your visibility.
Because of this, there are a lot of different warnings and errors that Google can show you. Watching for these, dealing with them when they show up, and taking steps to prevent them from happening again are all key parts of maintaining a healthy website.
While the internet is full of resources and guides to fix specific errors, there are very few guides on the complete list of possible errors. In part, this is because there are so many of them, but it's also partially because Google changes from time to time, and some errors appear or disappear at their whim. I've decided to try to put together that kind of ultimate guide here for you today.
If an error has appeared in your Google Search Console that I haven't covered, please let me know in the comments so I can add it to the list!
Let's dig right in.
HTTP Status Code Errors
The Hypertext Transfer Protocol is the foundational means of communicating data over the internet. HTTP, among other things, has numerical status codes to communicate between client and server or between servers. Some of them are the equivalent of "situation normal" while others are errors. The specific numerical code refers to the issue the servers detect.

Since the Google Search Console is able to see your website from the inside and the outside, they can check for various status codes and report to you when they find them. Individual URLs can have a status code error under your Pages report.
There are something like 63 different HTTP status codes, most of which will never show up in the Google Search Console because they either aren't errors, are deprecated, or aren't relevant.
1XX Informational Responses
HTTP status codes that start with the number 1 are informational responses and do not represent errors.

They're largely invisible to just about everyone because they mean everything is functioning normally.
- 100 Continue
- 101 Switching Protocols
- 102 Processing
- 103 Early Hints
None of these will appear in the Google Search Console or really anywhere else unless you're looking directly at server communication logs.
2XX Success
HTTP status codes that start with the number 2 are codes that indicate a successful communication in some way.

Again, these aren't errors, won't show up in the Google Search Console, and are generally only visible if you're looking at server logs. They're kind of the background radiation of the internet.
- 200 OK
- 201 Created
- 202 Accepted
- 203 Non-Authoritative Information
- 204 No Content
- 205 Reset Content
- 206 Partial Content
- 207 Multi-Status
- 208 Already Reported
- 226 IM Used
If you're interested in what all of these mean, there are excellent resources out there on the base-level server communication protocols you can read. I'm not digging into them because they aren't errors.
3XX Redirection
This is where we get into the first section that can have errors in the Google Search Console. The trick is that you almost never see these listed as an error. Instead, the Google Search Console lists things like "redirect chain," "redirect loop," or "incorrect redirect" in their page status reports.
3XX status codes are redirect codes. They're very important for managing expectations and guiding traffic, but they can also be handled poorly or incorrectly in a way that hurts usability.
- 300 Multiple Choices
- 301 Moved Permanently
- 302 Found
- 303 See Other
- 304 Not Modified
- 305 Use Proxy
- 306 Switch Proxy
- 307 Temporary Redirect
- 308 Permanent Redirect
If you have a page at one URL and you want to change the URL it's on, you use a redirect. If you want to move a page temporarily but move it back later, you use a redirect. Redirects tell Google what's going on with the pages and help prevent them from deindexing a URL that will return or continuing to index a URL that you don't want to keep.

The errors you might see in the Google Search Console include:
Page with redirect. This just means the URL you're looking at has a redirect on it. Google won't index that page because anyone landing on it will be redirected elsewhere. If the redirect is temporary, they'll keep it in mind and check to see if the redirect is removed later. If the redirect is permanent, that URL won't be indexed.
Redirect chains. If a redirect points to a page that also has a redirect on it, that's a redirect chain. This was often used as a malicious tool to send users through a bunch of interstitial pages with ads before reaching their destination. Google will choose not to index a page with a redirect chain if they can avoid it.
Redirect loops. If page A redirects to page B, and page B redirects to page A, that's a redirect loop. These are fairly rare, but if they occur, users end up in an infinite loop of redirects. Obviously, this isn't useful for anyone, so Google won't index those pages until the redirects are fixed.
Incorrect redirects. This is a tricky one; if you redirect from a page to a different page, but the content of the different page is largely irrelevant (such as if I redirected the page you're reading now to a guide on writing content), Google won't like it. It's basically a bait-and-switch for search results. Redirect should be set up to point to as relevant a page as possible.
Another common issue is using the wrong kind of redirect, even if you're using it correctly. The biggest example is the difference between 301 and 302, the temporary and the permanent redirects. Both are valid but have different purposes and using the right one for the right purpose is required. I have a whole guide to using them properly (as well as a discussion of whether or not you should be using 307 or 308 instead), which you can read here.
4XX Client Errors
Errors starting with 4 are client errors, though the error can be something like "the user requested a page that doesn't exist." The most common errors are things like 403 Forbidden, which is a page that exists but the client doesn't have authorization to access it, or 404 Not Found, which is a URL that doesn't exist.
- 400 Bad Request
- 401 Unauthorized
- 402 Payment Required
- 403 Forbidden
- 404 Not Found
- 405 Method Not Allowed
- 406 Not Acceptable
- 407 Proxy Authentication Required
- 408 Request Timeout
- 409 Conflict
- 410 Gone
- 411 Length Required
- 412 Precondition Failed
- 413 Payload Too Large
- 414 URI Too Long
- 415 Unsupported Media Type
- 416 Range Not Satisfiable
- 417 Expectation failed
- 418 I'm a teapot
- 421 Misdirected Request
- 422 Unprocessable Content
- 423 Locked
- 424 Failed Dependency
- 425 Too Early
- 426 Upgrade Required
- 428 Precondition Required
- 429 Too Many Requests
- 431 Request Header Fields Too Large
- 451 Unavailable for Legal Reasons
Among all of these, generally, the Google Search Console is only interested in 401, 403, and 404.

401 errors show up in the Google Search Console as "Blocked due to unauthorized request (401)". For example, if the page is protected by a password, Google's crawlers (and unauthorized users) can't access it, so Google won't want to show it in the search results. To fix the issue, you either need to noindex the page or remove the authentication gate. Alternatively, there's some kind of crawler or IP blocking preventing the Googlebot from accessing the page; removing that barrier will address the error the next time Google tries to index the page.
403 errors are cases where the server is blocking the request, and access is forbidden. This can be due to errors in your .htaccess file, issues with plugins, a malware infection, or even issues with IP addresses. It's one of the more complicated issues to solve, but fortunately, it's also quite rare. Check for malware on your site or configurations that block a Googlebot IP, and that covers most of your bases.
404s are the general "this page doesn't exist" error. They come in two forms: hard 404s and soft 404s. In the Google Search Console report, hard 404s are listed as Not Found (404), whereas a soft 404 is just "Soft 404".
A hard 404 is simply a blank page with the server error on it. It's actually difficult to find modern examples of these because many CMSs today will, by default, create a customizable 404 page (like mine at https://www.contentpowered.com/404/) as a way to help refer people to more useful pages instead of bouncing them. That customizable page – a page that has content and loads with a correct 200 response code but is a blank page that clearly isn't where the user wanted to be – is a soft 404.
To fix hard 404 errors, determine why they're happening. Someone, somewhere, is following a link that doesn't exist. It might be a typo, in which case you can redirect the typo page to the real page. It might be a page you removed, in which case you can use a 30X redirect as described above. It might be spam or nonsense, in which case you can redirect it to your homepage.
Soft 404s are harder, both because you might not be able to identify them as easily until an error shows up and because you might want the soft 404 fallback. Start by checking if the page is actually a soft 404 or just a thin page Google has misidentified. Check if you have other pages redirecting to a page that doesn't exist, and fix that if it's happening. It's also possible that your soft 404 is intentional, and you don't have much you can do about it.
5XX Server Error
The 5XX errors are generally issues with the server hosting your website. A server being DDoSed, a server where the configuration has been corrupted or where the hardware is failing, and other similar situations can cause 5XX errors.
- 500 Internal Server Error
- 501 Not Implemented
- 502 Bad Gateway
- 503 Service Unavailable
- 504 Gateway Timeout
- 505 HTTP Version Not Supported
- 506 Variant Also Negotiates
- 507 Insufficient Storage
- 508 Loop Detected
- 510 Not Extended
- 511 Network Authentication Required
Google's Search Console doesn't really care what error occurs here; they lump them all into "Server error (5XX) in their list. That's because, from the perspective of an outsider, it doesn't matter which error is happening; it all blocks the page from loading.

To fix this, you generally need to contact your web host and ask them to figure out why your site isn't available. Most of the time, it's either an issue with something they did, a DDoS somewhere on their service, or failing hardware. In rare cases, it might be a configuration you set and broke, in which case you need to roll it back or fix it.
There are also a lot of unofficial codes, either used by specific platforms like Shopify or Apache, established more as jokes, or deprecated over time. Google doesn't report any of these, so you can generally ignore them, at least for the purposes of this post.
Crawling and Indexation Errors
Perhaps the biggest category of errors, and the most common issues you might encounter, are crawling and indexation errors.

These are the collective group of errors that occur when the Googlebot tries to crawl your site and runs into some kind of problem.
URL Blocked by Robots.txt
The robots.txt file is a text file you place in your website's root directory. It allows you to give instructions to web-crawling robots (of which there are many), which lets you hide pages you don't want in the search index. Blocking certain pages from the crawlers is good for, say, blocking attachment and tag pages that would show up as thin content in Google's algorithm.
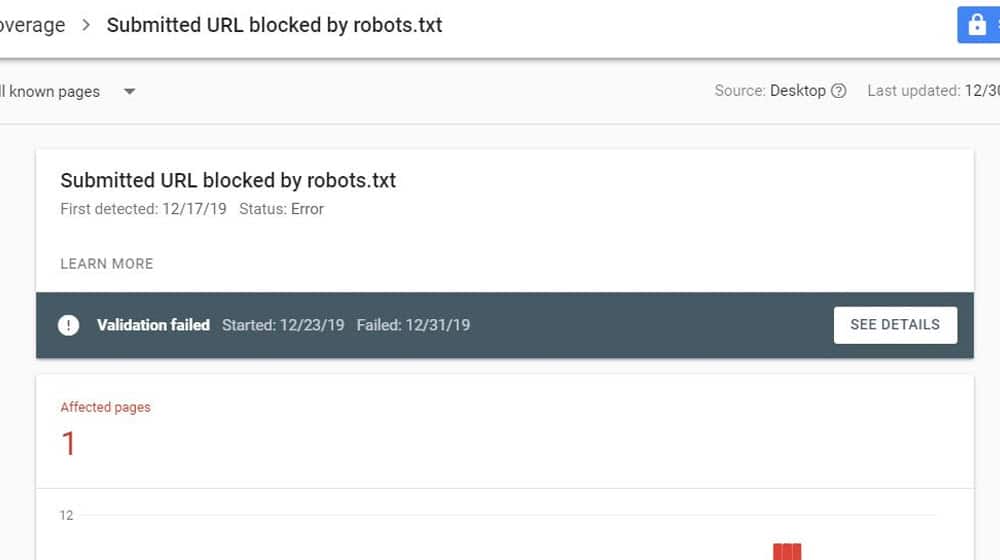
It's easy to accidentally block pages in robots.txt that you didn't want to be blocked. It's even easy to accidentally block everything on your site. Fortunately, it's easy to fix. You can just edit the file directly or use a tool to validate and test it to see what it's actually doing.
If a page you want visible is blocked by robots.txt, fix the entry that blocks it, save the robots.txt file, and request reindexation.
Indexed, Though Blocked by Robots.txt
This one is closely related to the above but involves a bit of a timing issue or a post-hoc change. It means that Google has crawled and indexed the page, but robots.txt now says not to. This can happen if Google indexed the pages and you later added a robots.txt to stop them from doing so.
When this happens, the page will still appear in the Google search results for a while but will have no information available in the meta description. Eventually, when Google refreshes that part of their index, the URL will drop entirely.
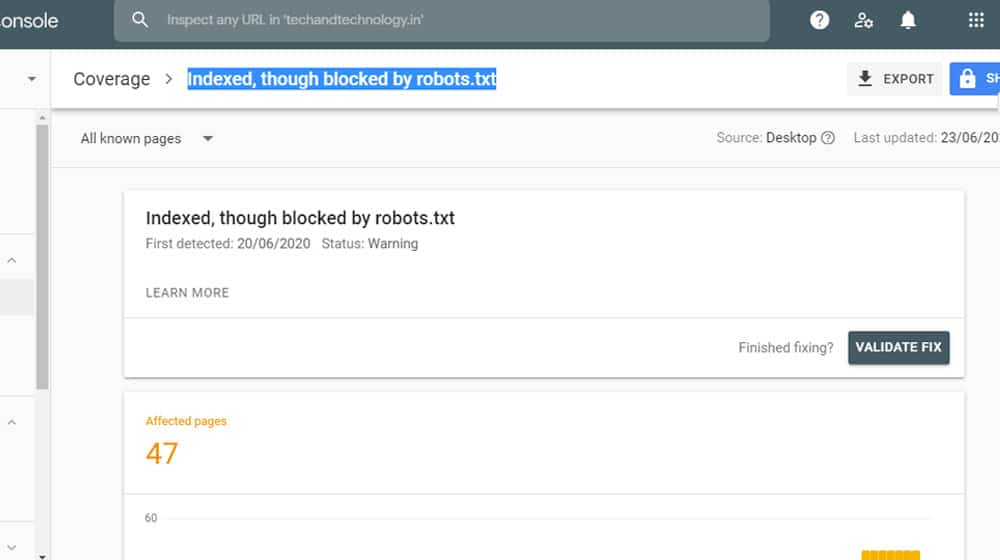
If you want the page to be removed from the index, you can let this happen, or you can request a removal from the index directly. This is the go-to option for pages that include sensitive content or otherwise shouldn't be visible, for example.
If you want the page to be indexed, you need to find the entry in the robots.txt that blocks it and remove it. When Google refreshes, they'll notice they have access again and can restore the page to the index properly.
URL Marked NoIndex
One of the HTML meta commands you can put on a given page is the noindex command. This works in a similar way to the robots.txt but is distributed.
What do I mean? If you have ten pages you want to be blocked from the index, you can put ten individual lines in your robots.txt file so they're all in one place. Or, you can put the noindex directive on each page. It's best practice to put it in a robots.txt file because it's a lot easier to edit if it's all centralized. Otherwise, you have to have the full list of pages you've added the directive to, and go make manual edits to each when you want to change it.
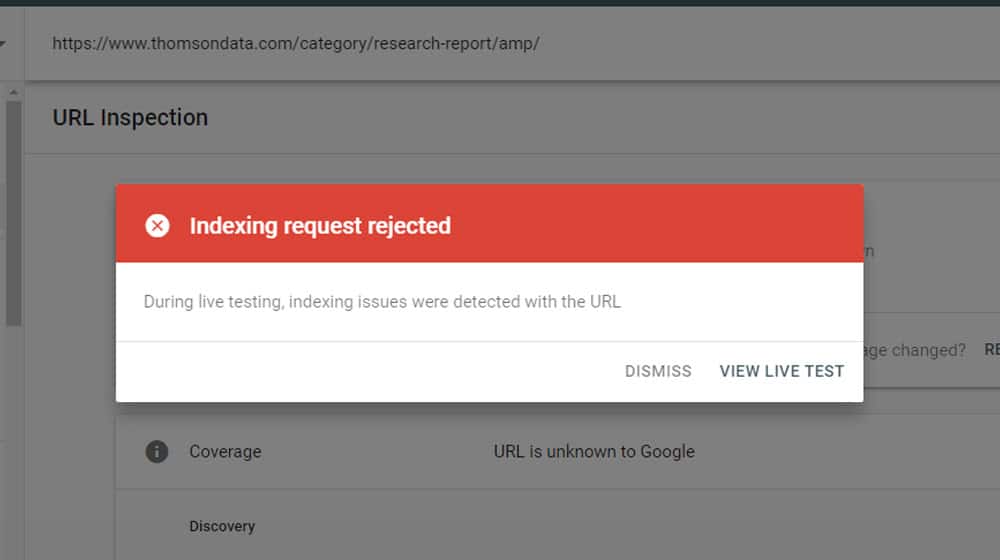
When the URL Marked NoIndex error shows up, it's generally because you have the page listed somewhere Google can find, like your sitemap or an internal link elsewhere on your site, but when they try to crawl it, they run into the noindex directive.
Fortunately, the solution is simple. If you want the page to be visible, remove the noindex tag. If you don't want it to be visible, remove it from wherever Google was finding it.
Blocked by Page Removal Tool
Google has a tool called the Page Removal Tool. This allows you to put a URL into their system as one you want them to ignore. It can be because you're hiding it temporarily while you fix it, it's outdated and you want to focus on a newer version of the page, or similar reasons.
When you put a URL into this tool, Google adds it to a list of pages they know about but don't index. That naturally means the URL shows up in the Google Search Console as known but not indexed. Fortunately, the solution is simple: go back to that tool and remove the URL. This is something you would have had to do intentionally, after all.
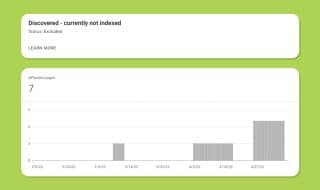
Discovered – Not Currently Indexed
This is one of the more frustrating errors you can find in the Google Search Console URL report. This means that Google knows your URL exists but that, for some reason, they have not crawled it yet and have not indexed it. While this is often the case for a brand-new URL they'll get around to crawling in their next pass of your site, it can also be the status for pages that are months or even years old. It's extremely frustrating to have pages you spend time creating only for them to sit in limbo for ages.
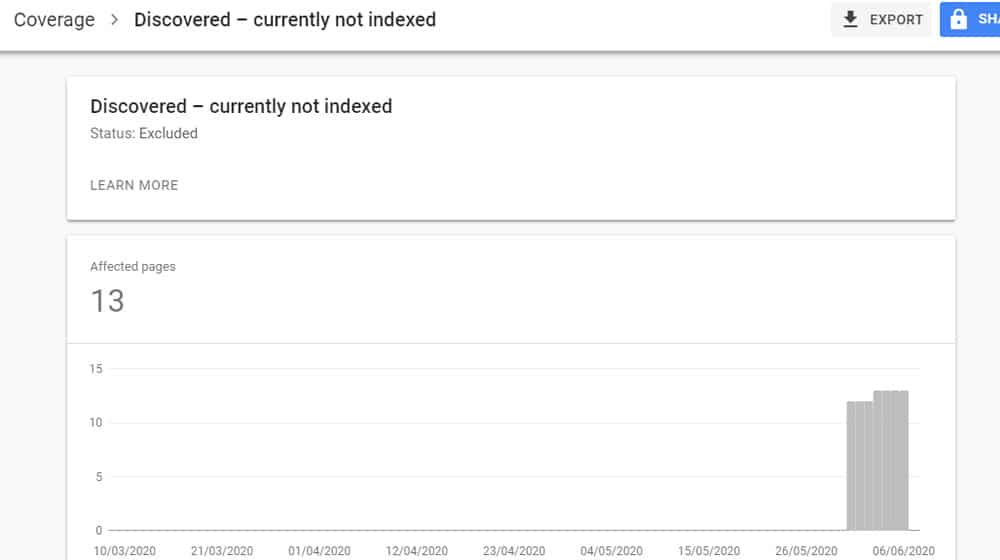
What causes this issue? Unfortunately, it can be just about anything.
- A technical issue is stopping Google from processing the page.
- Google has decided to exclude the page, or you have directives excluding it.
- Your website's structure is poor, and the crawlers miss it.
- Google is just saving resources and doesn't think your page is worth indexing.
- Google is saving your resources, and it is worried that a full crawl will slow down your server.
To fix this issue, start by making sure the page is in your sitemap. You can then go to the URL inspection tool in the Google Search Console and click the "request indexing" button. Ideally, this will trigger Google to index the page. Unfortunately, sometimes Google is obstinate and just won't listen to you, and there's not a ton you can do about it.
Crawled – Not Currently Indexed
This is similar to the above issue, except it's one step further and even more annoying. It means Google knows about your page and crawled it but has decided not to put it into their index. There are no other errors or roadblocks; they just decided to flip you off and ignore you.
Often, this happens if Google thinks the page is thin or low quality. They might also think it's not valuable enough. You can try to fix this by adding to the page, making it more useful or robust, or by adding more internal links to it. You can also work on link building and get external links to it as well.
You can also consider if the page is not quite on target. If you're targeting a specific keyword but you aren't matching search intent, you can run into this issue; try adjusting the content and see if that helps.
Canonicalization Issues
A problem that Google knows about and provides a tool to solve is cases where the same content can appear at multiple URLs for perfectly valid reasons. For example, a page using HTTP and a page using HTTPS and the same pages with and without the WWW in front of the URL all form four different distinct URLs, all with the same content.
To you and I, these are the same page. To the computer systems, these are four identical pages of copied content.
Now, usually, Google is smart enough to understand this. But it can also happen with things like URL parameters, upper and lower-case letters in the URL, having an index.html at the end of a URL, and other less obvious causes. Even cases where the same content is published on multiple domains can be legitimate, such as with syndication.
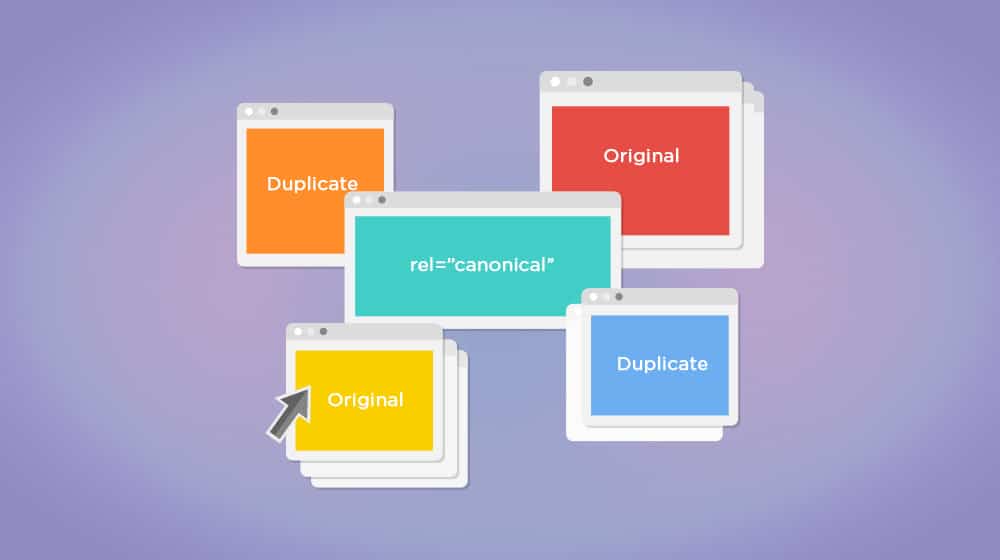
Google's provided tool is the rel=" canonical" tag. Pages that have content on a URL that isn't the intended URL can use the canonical tag to tell Google, "The real page is over here, but this one is intentional, so don't penalize me for it."
This can go wrong in a bunch of different ways, which can show up in the Google Search Console as errors.
Alternate Page With Proper Canonical Tag
First up, you can see this error on a URL. This is the "error" that shows up when you're looking at a URL that has a different canonical URL. The non-WWW version when you want WWW on everything, for example. This isn't something you need to fix, though you can get rid of it by using URL rewriting or redirects instead of canonicalization for the non-canonical pages when possible.
If you do want the page to be indexed for some reason, you need to go to the page and remove the canonical URL. Make sure the pages aren't actually duplicates if you do this!
Duplicate Without User-Selected Canonical
This is sort of the opposite; Google has identified cases on your site where multiple pages share identical content, but you don't have a canonical tag telling them which one is the "real" version of the page. This can happen quite easily, especially on large sites, so it's good to implement good canonicalization hygiene well in advance if possible.
When you see this error, you need to identify all of the URLs that point to the same content. Decide which one you want to be canonical and add the rel=" canonical" tag to all of them, pointing at the right one. Even the canon URL should have a self-referencing canonical.
Request a re-crawl, and Google will fix it when they see what you changed.
Duplicate, Google Chose Different Canonical Than User
This is an error that happens when there are a bunch of different pages with the same content, and you choose a canonical page, but Google disagrees and chooses a different one to be the canonical page. Isn't it great how Google can just choose to ignore your directives?
Sometimes, Google is right. If your whole website uses WWW and you canonized the non-WWW version for one page, they'll probably say, "Hey, that's wrong," and canonize the WWW version instead. Other times, they're just getting it wrong, possibly because your canon page doesn't have self-referential canonization or possibly because you have canonicalization on most but not all of the variations, so there are some gaps. Fix this by being thorough and requesting a re-crawl when you've fixed it all.
Mobile Usability Issues
Google has been taking the mobile internet much more seriously for the last several years since over 50% of internet use is done on mobile devices today.

Mobile-specific issues generally have to do with design and interaction.
- Clickable Elements Too Close Together. This means you have buttons, links, or other elements so close to each other or so small that a user trying to tap one has a good chance of missing. Google recommends that elements be at least 48 pixels and spaced at least 8 pixels apart.
- Viewport Not Set. This is an issue with your page not telling the browser how big the viewport should be. This is simple to fix; just add the viewport metadata as necessary.
- Content Wider Than Screen. This means your site needs horizontal rather than just vertical scrolling to see everything. Often, this happens when an image loads at full size and stretches the viewport. CSS can fix this, but you do need to figure out why it's happening.
- Text Too Small to Read. This means the text is too small to read, and the user would need to zoom in to read it. This often happens if you don't have a real mobile design or you use absolute font sizes. Instead, consider using relative font sizes so they scale with the viewport.
You can also view Google's recommended best practices for mobile accessibility in their mega site for accessibility on the web here.
Core Web Vitals Issues
Core Web Vitals are a set of metrics Google monitors that are closely related to page speed and loading.

Each metric can have associated warnings if they aren't up to snuff, and Google thinks you have room for improvement.
- LCP, or Largest Contentful Paint, is the delay between the start of a page loading and the time the largest chunk of content loads. This should be as short as possible.
- INP, or Interaction to Next Paint, is a measure of how well the page responds to user interaction. Does it need to finish loading before a user can click a button? That's usually bad.
- CLS, or Cumulative Layout Shift, is how many elements of the page move while other elements load. If you've ever loaded a page, started reading, and lost your place because a header image loaded and shifted everything down, that's an example of bad CLS.
Google will tell you if one or more of these are in the warning zone or the danger zone. You can fix it through technological improvements to your site or your code, though remember that it can take a bit of time to update, and you will need to fix both your desktop and mobile versions of your site.
Structured Data Warnings
Schema markup, found at schema.org, is a vast collection of pieces of structured metadata that you can add to your site to tell Google some information about it. This helps avoid issues where Google tries to read data for, say, a product page and misinterprets the SKU as the price and shows your product costing millions of dollars.

A page that uses Schema needs to make sure to use it properly. Otherwise, there can be issues that Google will detect and tell you about. For example:
- Missing field "SKU"
- Missing field "description"
- Missing field "video"
- Missing field "review"
You often find these with plugins that add data but add fields that you might not use. For example, one of the most common plugins for adding a recipe box for food blogs has Schema built into it, but it has a field for adding a video showing you prepare the recipe; if you don't have a video to add, leaving it blank will show that error in your Google Search Console report.
Since there are nearly 800 Schema tags with anywhere from a handful to dozens of parameters each, it's impossible for me to write down every possible issue here.
To fix it, just look at what data it's asking you to have and decide if it's data you should have tagged. If so, add and tag it properly. If not, well, it's just a warning, and you can generally ignore it. It's relatively rare that it's an essential piece of information that you don't have, after all.
Assorted Other Errors
There are also a handful of other errors or warnings that can show up but which don't fit nicely into one of the other categories.

Let's talk about them too!
Crawl Anomaly
When a URL has a "crawl anomaly," it means something went wrong with crawling it, but Google doesn't really know what. It could be a software bug, a temporary blip in connection, a strange configuration issue, or something else. The point is, not even Google knows what it is, just that it's weird.
Most of the time, these are temporary and go away on their own. Since there's no real information about them available, if you can load the URL fine, there's not really anything you can do about it.
Indexed But Not Submitted in Sitemap URLs
This is a simple one: Google found your page and indexed it properly, but it's not a page that's listed in your sitemap.
If you wanted the page indexed, just add it to your sitemap, and you're golden. If you didn't want the page indexed, go through and hit the noindex or robots.txt file to block it, and request a removal if it's urgent.
AMP (Accelerated Mobile Pages) Errors
AMP is a sort of stopgap way that Google was implementing to allow websites to create mobile-readable pages that load quickly without needing to make a whole mobile version of their site. They're largely obsolete with modern responsive design, and the best solution to these errors is to stop using AMP and make a modern design. If you insist on AMP, though, there are nearly 20 errors that can show up. Some of them are duplicates of errors above, while others are AMP-specific.
I'm not going to go through all of them here because, again, you should probably move away from AMP, but you can read Google's documentation of them here.
Video Issues
If you embed or host videos on your site, you might also run into video-related issues and warnings in the Google Search Console.

These include:
- No Thumbnail Provided. Videos should have a thumbnail image that shows when the video hasn't loaded. Generate this if you don't have one. (Embeds from sites like YouTube do this automatically.)
- Video Outside Viewport. This means some quirk of your site design pushed the video outside of the bounds of the browser window. Since this is often used as a malicious technique to scam video views, you need to fix it by making sure the video is inside the window.
- Unsupported Video Format. This means the video format you use isn't one of the supported types, like MP4, MPEG, or WEBM. A conversion fixes it.
You can also run into structured data issues with videos, too.
Security Issues
These errors only appear if Google detects signs of malicious code, hacking, or other problems on your site.

These errors include:
- Hacked Content. Google detects content that matches malicious content that you likely didn't put there, like hidden pharmacy pages, spam sites, attempts at script injection, or meaningless content injection.
- Malware and Software. Google finds software on your site that matches virus or malware definitions.
- Social Engineering. Your site has pages designed to look like another site's pages, which are used maliciously for phishing attacks.
Various security issues show up in their own report, and they can get your entire domain deindexed until they're fixed. You have a lot of work ahead of you figuring out what happened and how to fix it.
HTTPS Issues
Google prefers sites that use SSL encryption over sites that don't, indicated by HTTPS, instead of HTTP.

Making sure you have a valid SSL certificate and your pages use the HTTPS version is a rather simple matter. Google provides an HTTPS report that shows you how many pages are secured and how many aren't, so you can make sure to fix the ones without security.
Manual Actions
A manual action occurs when something is detected to be wrong with your site, and a human reviewer looks and agrees with the assessment. They're generally flags that a site has something unsavory going on with it, like previous link abuse, keyword spam, or other issues. They can be devastating for ranking and indexation, but they're generally all recoverable.

Manual actions can apply to individual pages or to whole domains. Google will generally tell you what the manual action is, what pages are affected, and even how to fix it, though they may not list every page on your site that is impacted if you have a lot of them.
Site Abused with Third-Party Spam
This manual action is generally triggered by user-generated content that isn't moderated. Third-party blog comment systems like Facebook and Disqus are the most common. Other causes can include third-party embedded social media, guestbook plugins, file uploading services, free page hosting, and other issues that users can abuse. If these feeds allow bots to post, and those bots post hundreds or thousands of spam messages, it devalues your whole site.

Moderate, clean up, or disable these avenues of third-party spam to fix the problem.
User-Generated Spam
This is effectively the same as the above, except it's for native blog comments or user profiles. The easiest way to clean it up is to just disable comments, at least until you clean them up.

Anti-spam plugins and moderation queues can also help moving forward. If you have user registration, you'll want to monitor who registers and use systems to validate new registrations as well.
Spammy Free Host
A decade or so ago, when web hosting was rare and more expensive, free web hosts would offer limited web space with the caveat that ads and other injections could be added to your pages.

The shadiest of these would have tons of spam or malicious code on them, and Google created this manual action to penalize them. It's almost never a thing anymore, though, since web hosting is so cheap now.
Structured Data Issues
This is another way you can have issues with Schema and other structured data markup.
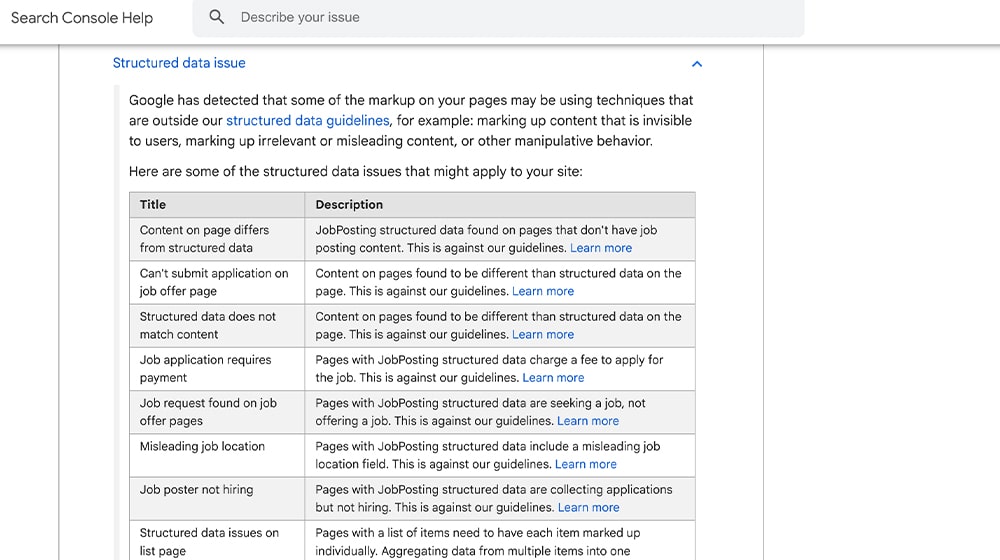
Google lists a ton of different examples, but really, anything that goes wrong with structured data can trigger this action. Just fix your structured data!
Unnatural Links To Your Site
This means you have an unnatural backlink profile like you were buying backlinks, participating in link wheels or exchanges, or otherwise trying to abuse linking for SEO purposes. Sometimes, you did it intentionally, sometimes, you didn't know better, and sometimes, you might not have even known it was happening. If you bought a website, it can also already be there as remnants of abuse from the previous owner.

Google recommends a multi-step process to fix this issue.
- Download your backlink profile and analyze it.
- Identify spammy or irrelevant/bad links.
- Reach out to the site owners of the pages linking to you and ask them to remove or nofollow the links.
- For links that you can't deal with that way, use the Disavow Links Tool to say, "Hey, I don't like these, but I can't do anything about them."
- Request reconsideration.
Be aware that Google will naturally filter a lot of bad links, so while they'll still appear in your backlink profile, they won't count for or against you. Overuse of the disavow tool can even hurt your SEO if you aren't careful, so use it as a last resort.
Unnatural Links From Your Site
If Google thinks your site is linking to other sites in an unnatural way, like through link schemes, link sales, or other issues, they can issue this manual action.

To fix it, identify the bad links and remove them, or at least nofollow them.
Thin Content With Little or No Added Value
Part of the Panda and Penguin updates in 2011 was a huge algorithm change that decided that thin, low-value pages are garbage and devalued them. When Google thinks you have thin content pages on your site, they can issue a manual action until you get rid of them. Examples include doorway and interstitial pages, content scraped from other sources, low-quality guest posts, and thin affiliate pages.

Get rid of the pages, noindex them, block them with robots.txt, or otherwise remove them from consideration to fix the issue and request reconsideration.
Cloaking And/Or Sneaky Redirects
Cloaking is the idea of showing one version of a page to Google and a different version to users, generally by redirecting one or the other based on user-agent detection.
Google isn't tricked by this and will penalize you for trying to scam them. Just don't do it.
Major Spam Problems
Scaled content abuse, cloaked content, egregious keyword spam, and other content spam policies can get your site penalized as well.
This is actually an increasingly relevant issue because low-quality AI-generated content counts as scaled content abuse.

There's not necessarily an easy way to fix this short of revamping or removing the content Google views as spam.
Cloaked Images
Another form of cloaking involves images. If you serve images that are hidden from Google and visible to users or hidden from users and visible to Google, this disconnect earns you a cloaking penalty.

This is often used as a way to try to abuse Google Image Search. Once again, just fix the cloaking and don't do it again.
For a long time, people have labored under the belief that specific keyword use and keyword density are important and that the more keywords you have for different related topics, the more you'll rank for them. Google's NLP updates killed this, but a lot of people still believe it to be true.

Spam techniques involving keywords would be things like hiding keywords behind an image, hiding them in size 0.1 font, hiding them with a font color the same as the background, or hiding them way off to the side of a page.
Get rid of stuffed keywords, and stop trying to trick Google.
AMP Content Mismatch
If you use AMP, and the content on your AMP page is different from the content on your real page, it shouldn't be.
Stop using AMP or fix the disconnect.
Sneaky Mobile Redirects
Sometimes, websites will have a perfectly functional desktop page but a mobile page that redirects to another URL. This was a more common spam technique when mobile internet usage was rare, but these days, it usually just means a compromised page.
Either way, you need your desktop and mobile pages to be nearly identical, save for small elements like positioning or image sizing. Make sure both versions of your site are the same.
Site Reputation Abuse
A relatively new addition, some major sites would offer subdomains or subsections of their site for users to create their own content on as a way to leverage their SEO power, usually in exchange for money.

Google doesn't like this kind of artificial user-generated value, so they've decided to penalize it.
Recovering from Manual Actions
All manual actions need effort to fix. Once you've addressed whatever issue occurred, you have to request reconsideration so Google can give your site another look and make sure you've fixed the problem.

Once that is done, your indexation and ranking will generally be restored. Sometimes, you even come out ahead, though if you had pages that were helping you rank but were deemed spammy, you might lose out in the transaction. Either way, it needs to be done if you want to continue operating your site.
Wrapping Up
There you have it: the most comprehensive list of Google Search Console warnings and errors I could possibly create.

What do you think? Did I miss anything? Do you need more information on something? If so, let me know in the comments, and I'll do my best to help!
Written by James Parsons
Hi, I'm James Parsons! I founded Content Powered, a content marketing agency where I partner with businesses to help them grow through strategic content. With nearly twenty years of SEO and content marketing experience, I've had the joy of helping companies connect with their audiences in meaningful ways. I started my journey by building and growing several successful eCommerce companies solely through content marketing, and I love to share what I've learned along the way. You'll find my thoughts and insights in publications like Search Engine Watch, Search Engine Journal, Forbes, Entrepreneur, and Inc, among others. I've been fortunate to work with wonderful clients ranging from growing businesses to Fortune 500 companies like eBay and Expedia, and helping them shape their content strategies. My focus is on creating optimized content that resonates and converts. I'd love to connect – the best way to contact me is by scheduling a call or by email.




Comments